http://yuji-ueda.hatenadiary.jp/entry/2015/12/21/010620 dockerに構築
https://qiita.com/isaoshimizu/items/9e47a82da9c465fc144a
OSXでのフエニクスだが参考になる
ちなみにhttp://blog1.erp2py.com/2011/05/web2py_17.html うえぶ2ぱい
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
https://qiita.com/sand/items/71d0b35d74a4781f3564 ecto―レジメ
https://qiita.com/sand/items/e98c9e98351b816c7e69 phoenixーレジメ
https://www.casleyconsulting.co.jp/blog/engineer/241/ phoenix intro
https://qiita.com/cohki0305/items/9641cfbe77e3e05e7e8d CRUD by Phoenix
http://ruby-rails.hatenadiary.com/entry/20151011/1444560106
フェニックスのためのセットアップが詳しい 三部作で認証やチャットも勉強できそう
-----------------------------------------
https://qiita.com/satosystems/items/e7fb4295598dc61e4c67
- 並列処理はかなり有効
- 並行処理もそこそこ有効(
forkIO) - 並列処理に迫る並行処理もあった(
async)
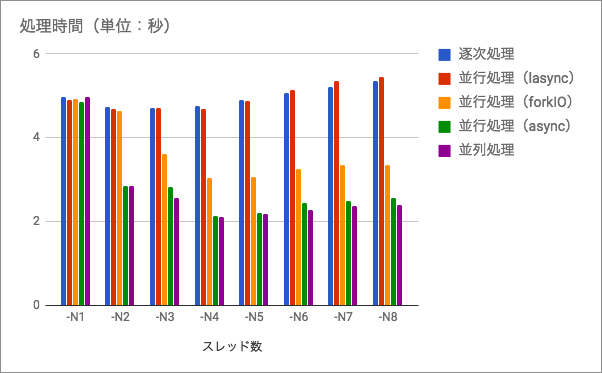
はじめに
Haskell で処理をマルチコアに分散したい場合どのようにすればよいかをまとめておきます。
負荷のかかる処理としてフィボナッチ数の導出を以下のように行うことにします。
fib :: Int -> Int
fib 0 = 0
fib 1 = 1
fib n = fib (n - 2) + fib (n - 1)
最適化に関して
まずは
fib 関数を普通に一回だけ実行します。once :: IO ()
once = print $ fib 42
この関数をシングルスレッドで動作させるとおよそ
2.877s かかります。引数の 42 は私の環境で早すぎず遅すぎない適当な値です。
今度は以下の関数をシングルスレッドで動作させてみます。
fourTimes1 :: IO ()
fourTimes1 = do
print $ fib 42
print $ fib 42
print $ fib 42
print $ fib 42
この実行には
2.879s かかりました。時間がかかるはずの関数を 1 回実行するのも 4 回実行するのもほとんど同じ時間です。この時 fib 関数は愚直に 4 回実行されずに何らかの最適化が働いているようです。
では 4 回
fib 関数を実行するのに以下のように行ってみます。fourTimes2 :: IO ()
fourTimes2 = mapM_ (print . fib) [42, 42, 42, 42]
この実行には
11.503s かかりました(ほぼ 4 倍の時間です)。fib 42 という形になっていないため最適化が行われないのでしょうか? では同様に mapM_ を使用した以下の関数ならどうでしょうか?fourTimes3 :: IO ()
fourTimes3 = mapM_ (\_ -> print $ fib 42) [(), (), (), ()]
この関数の実行は
2.862s で終わりました。想定どおりです。どうやら部分適用された関数は最適化されないようです1。
以下関数は
fib の引数がそれぞれ異なるので(おそらく)最適化が行われず、シングルスレッドで実行に 4.965s かかります。normal :: IO ()
normal = do
print $ fib 39
print $ fib 40
print $ fib 41
print $ fib 42
マルチスレッドではどうでしょうか? スレッドを増やした結果は以下のとおりです。
| スレッド数 | 時間 |
|---|---|
| -N1 | 4.965s |
| -N2 | 4.727s |
| -N3 | 4.702s |
| -N4 | 4.760s |
| -N5 | 4.890s |
| -N6 | 5.074s |
| -N7 | 5.211s |
| -N8 | 5.350s |
この関数を逐次処理とし、並行処理と並列処理の比較対象とします。
並行処理(forkIO)
逐次処理でシングルスレッドなら
4.965s かかる処理を forkIO で並行処理にすると、どれぐらいの時間で終わるのでしょうか? 実装は以下のようにしました。fork :: IO ()
fork = do
tv <- newTVarIO 0
_ <- fork' tv $ print $ fib 39
_ <- fork' tv $ print $ fib 40
_ <- fork' tv $ print $ fib 41
_ <- fork' tv $ print $ fib 42
atomically $ readTVar tv >>= flip unless retry . (== 4)
where
fork' :: TVar Int -> IO () -> IO ThreadId
fork' tv p = forkIO $ p >> atomically (readTVar tv >>= writeTVar tv . succ)
Haskell は
forkIO でスレッドを作成できるのですが、残念ながら他の言語の join のようなスレッドの終了を待ち合わせる機能は提供されていません。なので、面倒なのですが、スレッド化したい処理内でスレッドが終わったことをマークする必要があります。今回は TVar Int の値をインクリメントすることですべてのスレッドの終了を待ち合わせています。待ち合わせには retry という関数を使用していますが、TVar の値が変わるまでスレッドがブロックされるので待ち合わせで CPU リソースを消費するということはありません。
さて、この関数の実行時間は以下のとおりです。
| スレッド数 | 時間 |
|---|---|
| -N1 | 4.919s |
| -N2 | 4.638s |
| -N3 | 3.620s |
| -N4 | 3.049s |
| -N5 | 3.068s |
| -N6 | 3.246s |
| -N7 | 3.347s |
| -N8 | 3.349s |
4 スレッドまでは時間短縮し、それ以上になると若干時間延長しています。逐次処理と同じ傾向があります。スレッド起動等のオーバーヘッドでしょうか。今回は
forkIO でスレッド化した処理が 4 つだったので、4 あるいは 5 スレッドで並行化するのが最適であり、スレッドが多ければ良い、ということではなさそうです2。並行処理(async)
コメントで
async というパッケージを教えてもらいました。今回は以下のように使用しました。async :: IO ()
async = mapConcurrently_ (print . fib) [39, 40, 41, 42]
なんと並行処理が
mapM_ のように一行で記述できてしまいます。実行時間はどうなるでしょうか?| スレッド数 | 時間 |
|---|---|
| -N1 | 4.858s |
| -N2 | 2.848s |
| -N3 | 2.833s |
| -N4 | 2.123s |
| -N5 | 2.207s |
| -N6 | 2.440s |
| -N7 | 2.481s |
| -N8 | 2.574s |
効率に関しても
forkIO よりもかなり良いです。パッケージの実装を見ると、単に forkIO をラップしているわけではなさそうです。今回のケースで言えば、forkIO を使う理由が見当たりません。
並行処理(lifted-async)
async は並行処理が IO に依存しているため、他のモナド内で使用するには使い勝手が悪い場合がありますが、lifted-async を使用すれば様々なモナド内で並行処理が行えます。lasync :: IO ()
lasync = mapConcurrently (\a -> return $ fib a) [39, 40, 41, 42] >>= mapM_ print
上記コードは IO モナド内で実行しているためわかりづらいですが、
mapConcurrently に渡しているラムダから print が消えており、任意のモナドが使用できることがわかります。| スレッド数 | 時間 |
|---|---|
| -N1 | 4.912 |
| -N2 | 4.697 |
| -N3 | 4.716 |
| -N4 | 4.695 |
| -N5 | 4.881 |
| -N6 | 5.129 |
| -N7 | 5.359 |
| -N8 | 5.46 |
時間を計測してみたところ、冒頭のグラフでも見て取れるように、逐次処理と同じパフォーマンスしか出ていません3。
並列処理
並列処理ならどうなるでしょうか?
eval :: IO ()
eval = do
let as = parMap rpar fib [39, 40, 41, 42]
mapM_ print as
並行処理と比べ並列処理はかなり簡潔に記述できます。特に純粋な関数を純粋なまま並列化できるのが美しいです。この関数の実行時間は以下のとおりです。
| スレッド数 | 時間 |
|---|---|
| -N1 | 4.978s |
| -N2 | 2.857s |
| -N3 | 2.559s |
| -N4 | 2.103s |
| -N5 | 2.186s |
| -N6 | 2.281s |
| -N7 | 2.383s |
| -N8 | 2.386s |
かなり効率よく処理が行えているようです。-N4 を指定した処理時間が記事冒頭の
once という関数一回の処理時間(2.877s)より短いのは、冒頭の処理は -N1 を指定しているからであり、-N4 を指定すると 2.105s になります。つまりこの並行処理は最も計算時間のかかる fib 42 を行っている間に fib 39、fib 40、fib 41 の計算は他の CPU コアを使用して終わっている、ということを意味し、また並列化のオーバーヘッドがほとんどない、ということも表しています。まとめ
シングルスレッドで処理した場合、逐次処理、並行処理、並列処理はどれもほぼ同じ時間がかかります。スレッド数を増やすと並行処理、並列処理はその恩恵が得られ、特に並列処理のそれは顕著です。
Haskell(GHC)では、複数スレッドを用いると自動的に複数のコアが使用されます4。
forkIO を用いた並行処理でもスレッド数に応じたマルチコアが利用されているようではありますが、その効率は rpar を用いた並行処理には及びません。ただし async パッケージを使用した並行処理であれば、rpar とほぼ同等の効率を得られることもわかりました。
関数型言語と並行・並列処理は相性がよく、今回も実際目的の関数だけをかんたんに並行化・並列化することができました。うまく活用してマシンリソースを効率よく使用していきましょう。
なお、今回使用したソースコードは以下に置いてあります。
-----------------------------------------------------------------------------------mkdir mc
cd mc
git clone https://github.com/satosystems/mc
cd mc
stack build and thereafter....
$ stack exec mc -- normal +RTS -s -N4
$ stack exec mc -- fork +RTS -s -N4
$ stack exec mc -- async +RTS -s -N4
$ stack exec mc -- lasync +RTS -s -N4
$ stack exec mc -- eval +RTS -s -N4
0 件のコメント:
コメントを投稿